Substitution rules
Along with applying categorization rules to a conversation transcript, Conversation Analyzer applies substitution rules to refine the output. Substitution rules replace words that are often incorrectly transcribed and improve the spelling of words. You will most likely require these rules for proper nouns, such as place, company or product names. For example, Conversation Analyzer may transcribe 'Basingstoke' as 'Beijing spoke'. Create rules that replace the incorrect word or words. Substitution rules also replace sensitive information such as credit card details — you can, for example, replace specified text with text such as '(redacted)', '(removed)', or 'xxxxxxxxxxxxxx'.
Example categorization profile (substitution rules only)
In the following example, the categorization profile — SubstitutionRules — contains three substitution rules.
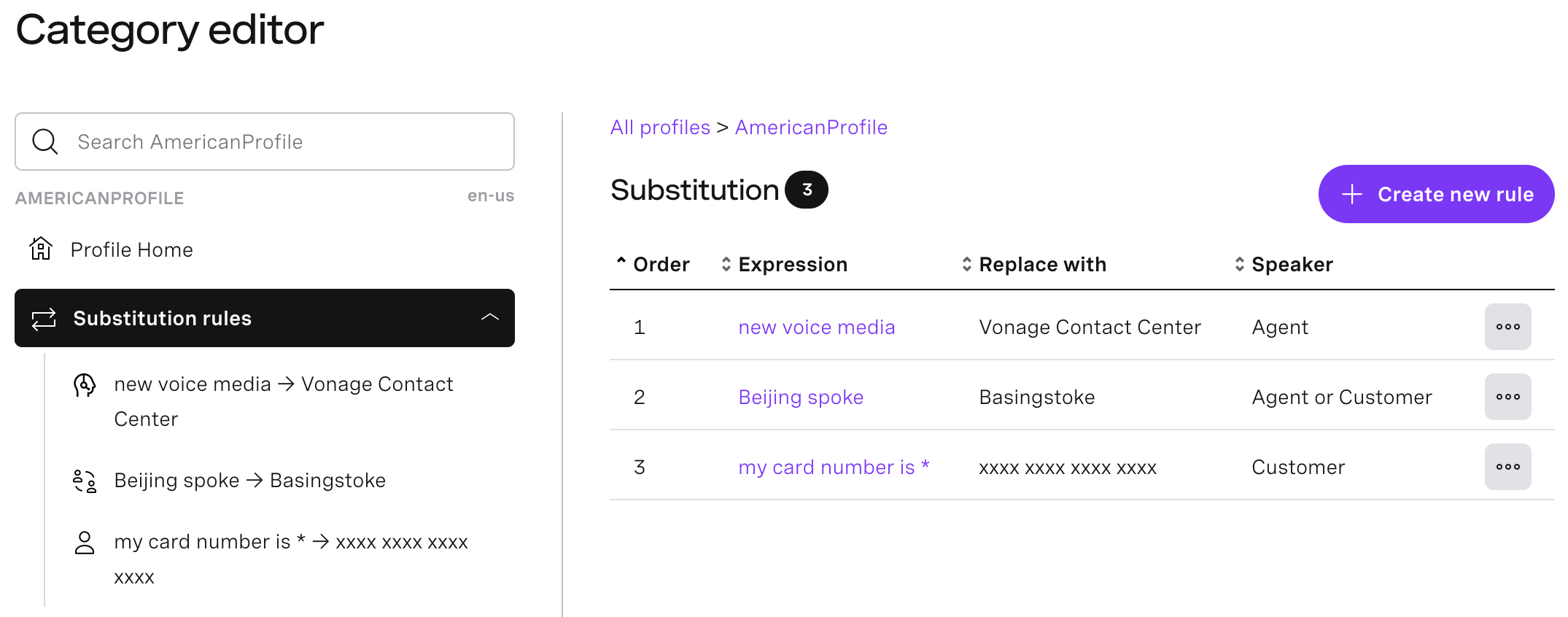
Expression
When creating or editing a substitution rule, define the value you want to replace in the Search phrase field. The value defines the text that must appear in the transcript to match the substitution rule.
The categorization expression language describes the format of the value in the Search phrase field. The language supports simple values where the presence of the exact word or phrase would result in a match. For information about writing expressions, see Categorization expression language in Categorization rules.
Replace with
When creating or editing a substitution rule, define the value that will replace the found text in the Replace with field.
Applying substitution rules results in Conversation Analyzer modifying transcript text. Because of this, you must take extra care when writing your rules.
Overlapping substitution rules
Overlapping occurs when more than one rule matches the same transcript text. Because substitution rules actually modify the transcript text, overlapping rules can cause a conflict whereby multiple rules try to replace text with different values. To handle overlapping, Conversation Analyzer uses the following logic when applying the rules:
- The order of the rules in the profile determine their priority; the first rule has the highest priority.
- If rules overlap, the higher priority rule takes precedence over the lower priority. The lower priority rule is discarded.
- A discarded rule does not block any other lower priority rules.
Chaining substitution rules
Chaining occurs when one rule matches the output of another rule. Chaining only occurs when you re-analyze a recording. For information about re-analyzing recordings, see Analyzing a call recording.
Each time Conversation Analyzer applies substitution rules to a transcript, Conversation Analyzer overwrites the original transcript with the processed text. Rerunning the substitution rules can therefore further refine the text.
Highlighting replaced text
After Conversation Analyzer has processed a transcript, substituting or redacting text as your rules require, you are unable to see what has changed. If you want to see where in the transcript Conversation Analyzer, for example, removed text, create a category that highlights the replaced text.
If you substitute text with characters that are not valid in Expression values, you will not be able to create a categorization rule to highlight the text. For example, if you create a substitution rule that replaces account numbers with *********, a categorization rule with Expression: ********* will be invalid.
For general assistance, please contact Customer Support.
For help using this documentation, please send an email to docs_feedback@vonage.com. We're happy to hear from you. Your contribution helps everyone at Vonage! Please include the name of the page in your email.